Querying Billions of GitHub Events Using Modal and DuckDB (Part 1: Ingesting Data)
Using Modal.com and DuckDB to download and query billions of public GitHub events from gharchive.org.


There have been two technologies I’ve been really excited about recently - and will jump at any excuse to use them. One is DuckDB, my new go-to for most local data processing, especially with the recent addition of a UI mode. DuckDB makes it very convenient to query fairly large (multiple GB) datasets on disk - CSVs, JSON files, etc. without having to write much boilerplate code. It’s also great for querying small JSON, like the output from an API request (or many requests).
The second is Modal, an infrastructure platform that truly feels like magic, which I’ll focus on more throughout this series.
This post and the following will demonstrate how to use Modal.com and DuckDB to ingest, process, and query huge amounts of public GitHub data (several terabytes of compressed JSON). It’s meant to serve as an example and introduction to these tools, and to show how well they work together!
This first post (Part 1) will cover how to use Modal’s highly concurrent, serverless infrastructure to download lots (50K+ files, 3.5 TB) of public GitHub data and store it on a Modal Volume - in about 15 minutes.
The GH Archive
Anyone who knows me, knows that I have a soft spot for querying git data with SQL - so when I came across the GH Archive again, I couldn’t help wanting to poke around to see what kind of queries I could run.
You can read more on the website, but the quick background is that it’s an open-source project that continuously archives public GitHub events (15+ types, such as git pushes, new issues, new PRs, stars, etc.), for all public GitHub repos, going back to 2011. That’s a lot of events!
The events are stored in gzip compressed JSON files and available for download at data.gharchive.org, partitioned by the hour - so each data file stores 1 hour of public GitHub event records. The URL format to access a data file looks like this:

GH Archive data is also available to query in BigQuery - but that’s no fun, let’s roll our own setup!
Downloading Lots of JSON
It’s great that we can access these files, but how can we actually query and analyze their content?
DuckDB can query remote data sources over HTTP(s) using the httpfs extension, and this is actually very cool. In fact, combined with the ability to decompress and handle line-delimited JSON on the fly, you could just run a simple query like so:
SELECT * FROM 'https://data.gharchive.org/2015-01-01-15.json.gz';To treat that single hour of event data as a table. The file is “downloaded” as the query executes (it’s also decompressed and each line of JSON is mapped into a schema, inferred by sampling the JSON attributes). The output will look like this:
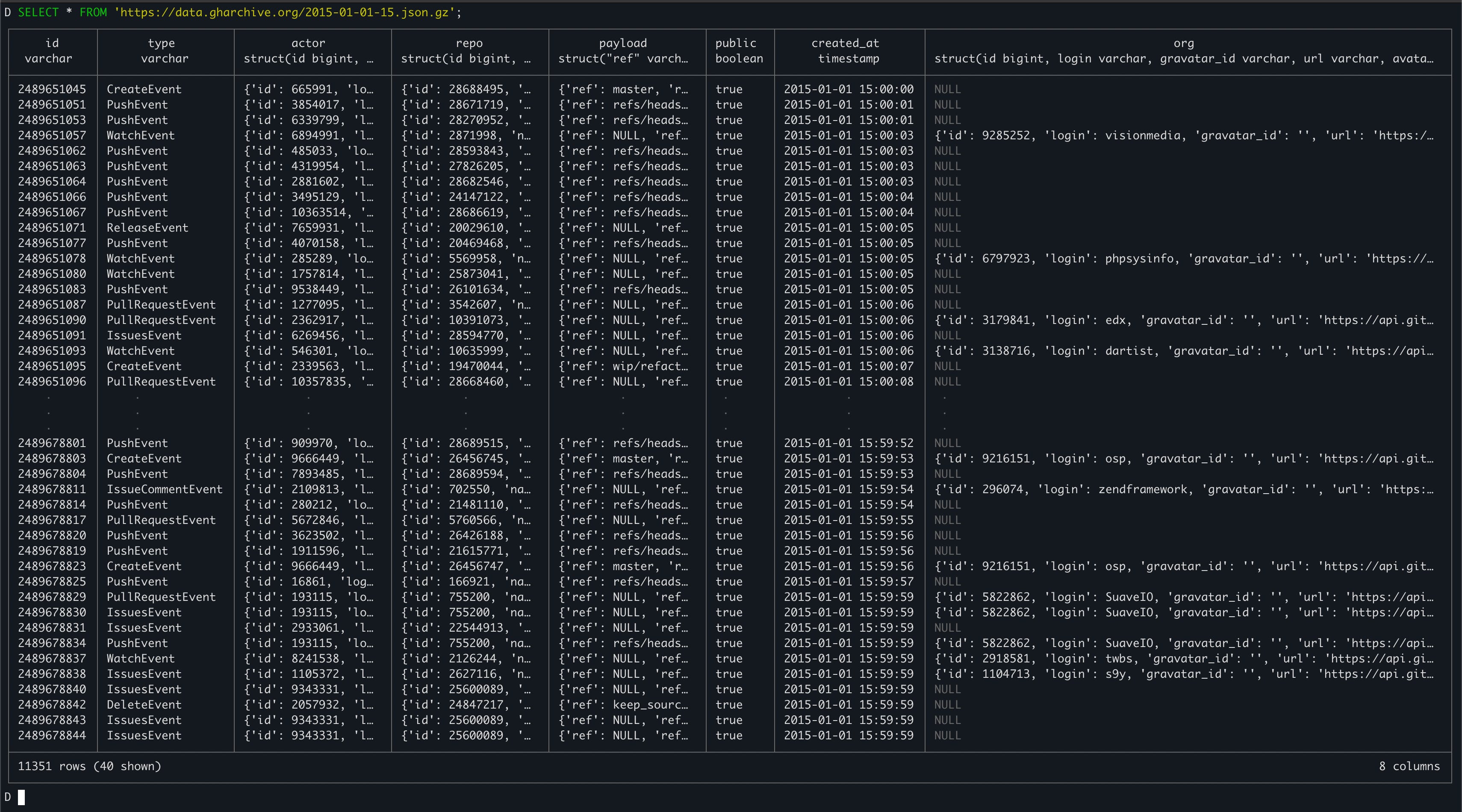
However, given that we want to execute queries across a lot of these files (let’s say over 1 year: 365 days * 24 hours = 8760 files) we’re probably going to want to download these files ahead of time. Storing them on disk and pre-processing them will certainly lead to faster querying - we don’t want to be waiting for thousands of network requests as our queries execute! Not only would this be really slow, it wouldn’t be very reliable either.
I’ll skip ahead and show you where we end up, which is every json.gz file from 2020 to now (August, 2025) stored on disk (a Modal Volume), in a folder structure organized by year, month, then day, where each file is named from {0-23}.json.gz, indicating the hour of the day. You can see that it takes up quite a bit of space on a Modal Volume: ~3.5 TB total. You can also see the slow growth in data size by year (corresponding to the overall user/activity growth of GitHub).
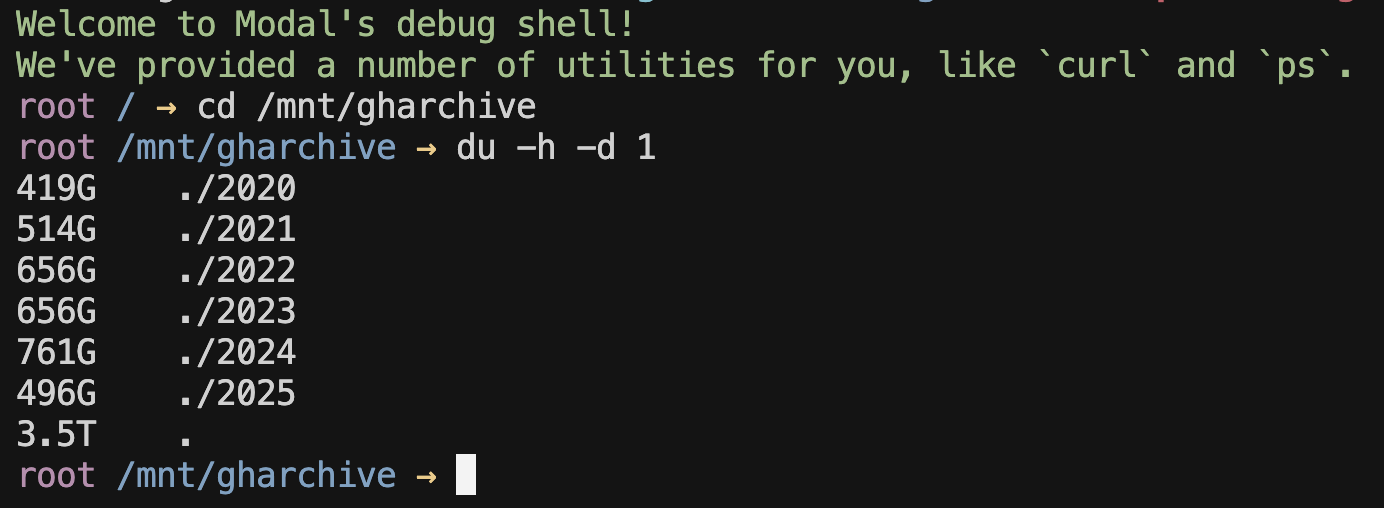
All of this data was downloaded in ~15m using Modal’s highly concurrent infrastructure. The files are stored in a Modal Volume, a filesystem primitive which can be conveniently attached to other functions (and even Modal Notebooks!).
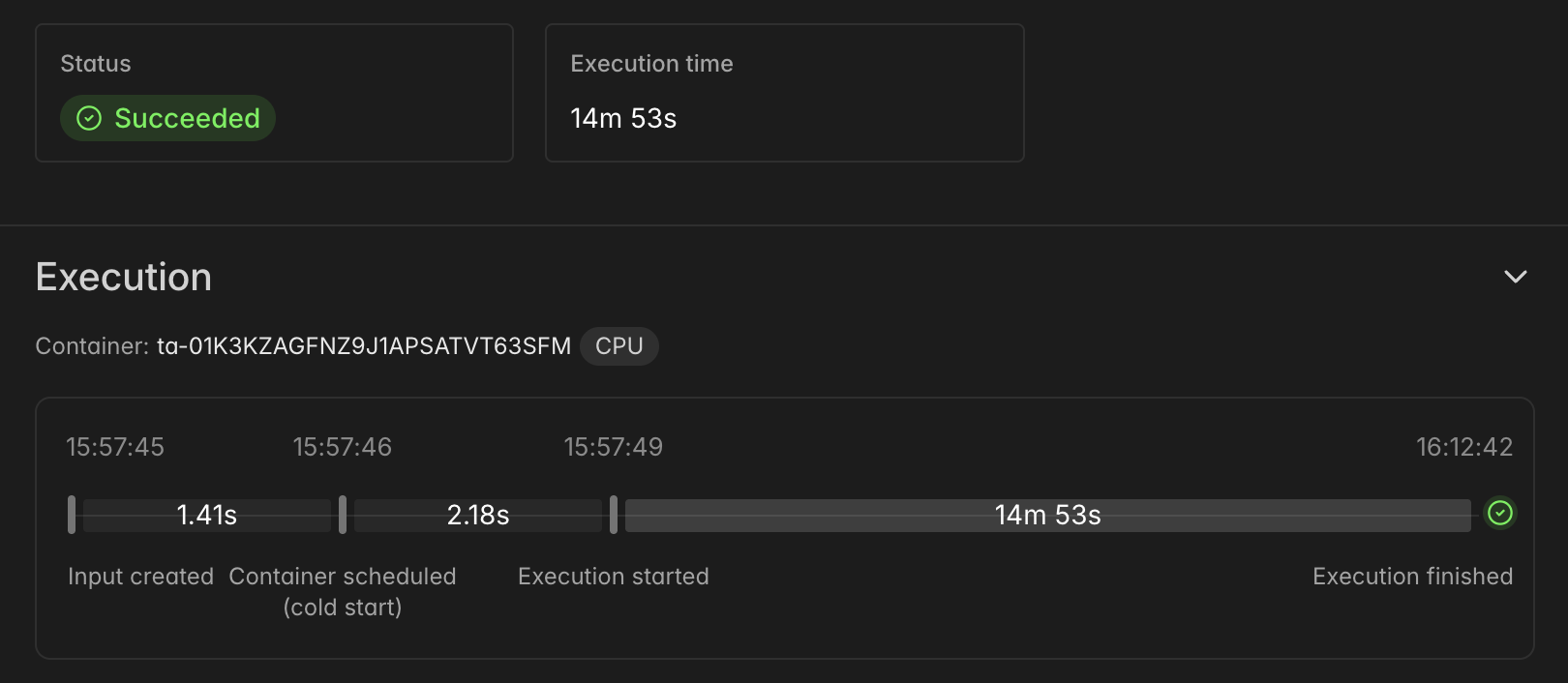
Here’s what the execution of the “parent” function (more on this in a moment) looks like, showing the timeline of the full download:
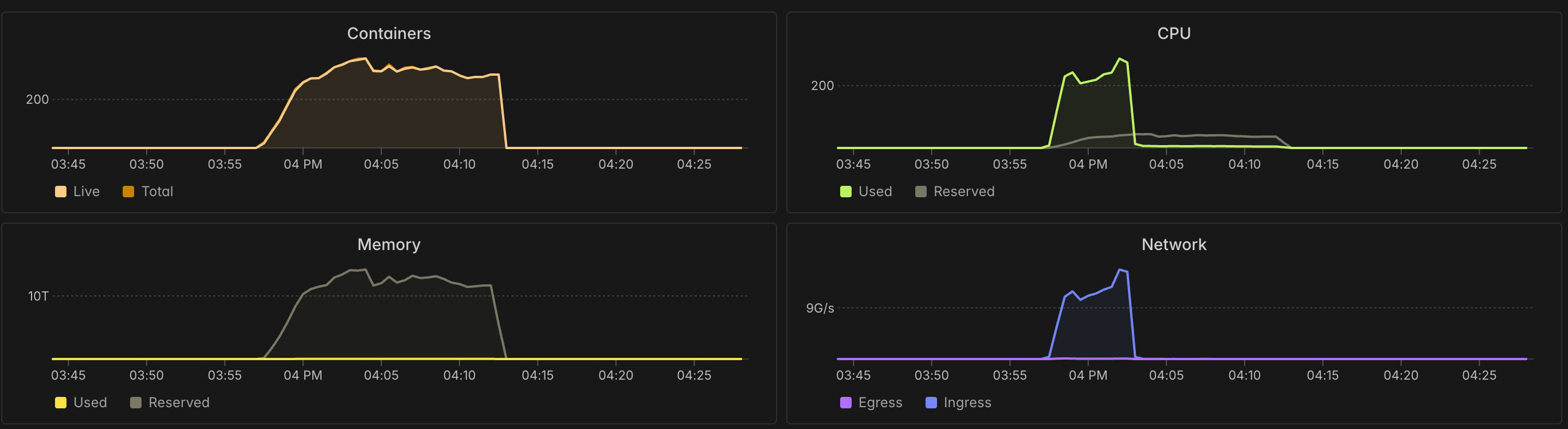
And here’s a screenshot of the Modal monitoring UI, showing resource utilization during the download run. Note the 300+ containers that were spun up and executed concurrently.
Parallelizing Downloads
Because GH Archive breaks out data into 1 hour chunks (1 file per 1 hour), we’re able to massively parallelize the overall download process - and this is where Modal can really shine.
Instead of spinning up a single big VM (or bare-metal server), or a Kubernetes cluster running a bunch of workers (and writing lots of YAML along the way…), we just decorate some Python code and instruct Modal to do a large fan-out for us, even handling retries with exponential back-off (important for dealing with network requests)!
This is where Modal really starts to feel like magic - and it’s probably easier to show rather then tell, but here’s a basic overview before I show you the code:
We define a function called
download_filedecorated with@app.function, indicating to Modal that it can be executed remotely. This function will handle the download of a single data file (1 hour of events). It will download the file into/tmp(attached disk), and then copy it into the Modal Volume, according to the recommendations here. This is the function that will execute many times in parallel, across hundreds of containers (for different inputs of year/month/day/hour combinations).A “parent” function called
download_rangeis responsible for generating the inputs for the calls todownload_filethat represent the time range we want to download data for. This does some calendar math to produce the set of year/month/day/hour combinations. Then, it uses .starmap(…) to have Modal executedownload_filefor all of those inputs in parallel!Finally, a
mainfunction decorated with@app.local_entrypoint()callsdownload_range.remote(date(2020, 1, 1)), this tells Modal to start the download process for all files from Jan 1, 2020 until today.
Here’s some code!
| import modal | |
| from datetime import date | |
| from .app import app, gharchive, GHARCHIVE_DATA_PATH | |
| @app.function( | |
| volumes={GHARCHIVE_DATA_PATH: gharchive}, | |
| timeout=36000, | |
| retries=modal.Retries( | |
| max_retries=8, | |
| backoff_coefficient=2, | |
| initial_delay=1, | |
| max_delay=30, | |
| ), | |
| ephemeral_disk=800 * 1024, | |
| ) | |
| @modal.concurrent(max_inputs=12) | |
| def download_file(year: int, month: int, day: int, hour: int) -> tuple[str, float, int]: | |
| import os, time, tempfile, shutil, pycurl, random, io | |
| # Tiny jitter to avoid synchronized bursts (helps with WAF/rate shaping) | |
| time.sleep(random.uniform(0.01, 0.05)) | |
| # URLs & paths | |
| url = f"https://data.gharchive.org/{year}-{month:02d}-{day:02d}-{hour}.json.gz" | |
| vol_path = f"{GHARCHIVE_DATA_PATH}/{year}/{month:02d}/{day:02d}/{hour}.json.gz" | |
| # Stage to a temporary file in /tmp which is on the attached SSD, as recommended in Modal docs: https://modal.com/docs/guide/dataset-ingestion | |
| tmp_dir = f"/tmp/{year}/{month:02d}/{day:02d}" | |
| os.makedirs(tmp_dir, exist_ok=True) | |
| fd, tmp_path = tempfile.mkstemp( | |
| dir=tmp_dir, prefix=f"{year}-{month:02d}-{day:02d}-{hour}.json.gz." | |
| ) | |
| os.close(fd) | |
| # Configure curl | |
| c = pycurl.Curl() | |
| c.setopt(c.URL, url) | |
| c.setopt(c.FOLLOWLOCATION, 1) | |
| c.setopt(c.HTTP_VERSION, pycurl.CURL_HTTP_VERSION_2TLS) # allow HTTP/2 | |
| c.setopt( | |
| c.USERAGENT, "gharchive-downloader/1.0 (contact: patrick.devivo@gmail.com)" | |
| ) # may help with rate limiting | |
| c.setopt(c.NOSIGNAL, 1) | |
| c.setopt(c.CONNECTTIMEOUT, 10) | |
| c.setopt( | |
| c.TIMEOUT, 60 * 5 | |
| ) # total timeout - most downloads should occur within this | |
| c.setopt(c.LOW_SPEED_LIMIT, 20_000) # bytes/sec | |
| c.setopt(c.LOW_SPEED_TIME, 20) # if below limit for 20s -> timeout | |
| hdr_buf = io.BytesIO() | |
| c.setopt(c.HEADERFUNCTION, hdr_buf.write) | |
| # Execute the download → /tmp, then fsync for durability | |
| with open(tmp_path, "wb", buffering=1024 * 1024) as f: | |
| c.setopt(c.WRITEDATA, f) | |
| c.perform() | |
| f.flush() | |
| os.fsync(f.fileno()) | |
| # Telemetry from curl | |
| status = int(c.getinfo(pycurl.RESPONSE_CODE)) | |
| size_b = int(c.getinfo(pycurl.SIZE_DOWNLOAD)) | |
| total_s = float(c.getinfo(pycurl.TOTAL_TIME)) | |
| mbps = float(c.getinfo(pycurl.SPEED_DOWNLOAD)) / (1024 * 1024) | |
| ttfb_s = float(c.getinfo(pycurl.STARTTRANSFER_TIME)) | |
| headers_s = hdr_buf.getvalue().decode("latin1", errors="replace") | |
| c.close() | |
| # Handle non-200s | |
| if status != 200: | |
| # Clean partial temp file | |
| try: | |
| os.remove(tmp_path) | |
| except FileNotFoundError: | |
| pass | |
| # Sometimes there's missing hours, but raise on 404 anyways to retry and report | |
| if status == 404: | |
| time.sleep(random.uniform(0.5, 2.0)) | |
| raise RuntimeError(f"HTTP 404 for {url} (retryable)") | |
| # Transient / retry-worthy codes → raise so Modal retries | |
| retry_statuses = {403, 429, 500, 502, 503, 504} | |
| if status in retry_statuses: | |
| first_hdr = headers_s.splitlines()[0] if headers_s else f"HTTP {status}" | |
| raise RuntimeError(f"HTTP {status} for {url} ({first_hdr})") | |
| # Other client errors: surface as failures (Modal will retry) | |
| raise RuntimeError(f"HTTP {status} for {url}") | |
| # Publish into the Modal volume atomically | |
| vol_dir = os.path.dirname(vol_path) | |
| os.makedirs(vol_dir, exist_ok=True) | |
| tmp_dest = vol_path + ".part" | |
| with ( | |
| open(tmp_path, "rb", buffering=1024 * 1024) as rf, | |
| open(tmp_dest, "wb", buffering=1024 * 1024) as wf, | |
| ): | |
| shutil.copyfileobj(rf, wf, length=8 * 1024 * 1024) | |
| wf.flush() | |
| os.fsync(wf.fileno()) | |
| os.replace(tmp_dest, vol_path) # atomic within the same FS | |
| dfd = os.open(vol_dir, os.O_DIRECTORY) | |
| try: | |
| os.fsync(dfd) | |
| finally: | |
| os.close(dfd) | |
| # Clean local temp | |
| try: | |
| os.remove(tmp_path) | |
| except FileNotFoundError: | |
| pass | |
| print( | |
| f"{os.path.basename(vol_path)} — {size_b / 1_048_576:.1f} MB " | |
| f"in {total_s:.2f}s @ {mbps:.2f} MB/s (TTFB {ttfb_s:.2f}s) → {vol_path}" | |
| ) | |
| return vol_path, total_s, size_b | |
| @app.function(timeout=36000, volumes={GHARCHIVE_DATA_PATH: gharchive}) | |
| def download_range(start: date, end: date = date.today()): | |
| from datetime import timedelta | |
| import time | |
| # Build hour-level inputs | |
| inputs = [] | |
| delta = end - start | |
| for d in range(delta.days + 1): | |
| day = start + timedelta(days=d) | |
| for hour in range(24): | |
| inputs.append((day.year, day.month, day.day, hour)) | |
| print( | |
| f"Downloading events from {start} to {end} — {len(inputs)} files over {delta.days + 1} days" | |
| ) | |
| t0 = time.time() | |
| total_size = 0 | |
| ok = 0 | |
| failures = [] | |
| for result in download_file.starmap( | |
| inputs, | |
| return_exceptions=True, | |
| wrap_returned_exceptions=False, | |
| order_outputs=False, | |
| ): | |
| if isinstance(result, Exception): | |
| failures.append(result) | |
| else: | |
| _, _, sz = result | |
| total_size += sz | |
| ok += 1 | |
| elapsed = time.time() - t0 | |
| total_gb = total_size / (1024**3) | |
| agg_gbps = (total_gb / elapsed) if elapsed > 0 else 0.0 | |
| print( | |
| f"Done: {ok}/{len(inputs)} files in {elapsed:.1f}s — {total_gb:.2f} GB total, avg {agg_gbps:.2f} GB/s" | |
| ) | |
| if failures: | |
| print(f"Encountered {len(failures)} failures (Modal handled retries): ") | |
| for f in failures: | |
| print(f"[FAIL] {f!s}") | |
| gharchive.commit() | |
| @app.local_entrypoint() | |
| def main(): | |
| download_range.remote(date(2020, 1, 1)) |
You can see there’s actually quite a bit going on, even though it’s a single file with <200 LOC:
We’re using
pycurl, Python bindings to cURL, which has been benchmarked to be faster thanrequestsWe configure it to “fail fast” on flaky downloads, allowing Modal to retry with an exponential back-off. This was key to improving overall performance and reliability - sometimes a download will get “stuck” or a connection gets reset. So instead of waiting out a slow download stream, we just end it quickly and try again (up to 8 times).
We handle and report 404s - it turns out there are some data files (hour chunks) missing from the GH Archive dataset. We retry these downloads, but if they are truly missing, we just report the 404s at the end of the run.
We track download speed, errors, total time, etc. and log as the downloads execute and as a summary at the end of the run.
We use
@modal.concurrent(max_inputs=12)to allow for concurrency within a container - Modal will run ourdownload_filecall up to 12 times at once in a single container. This allows a single container to do more work, and is a useful knob for tuning performance trade-offs.
Here’s what the output of this code looks like (just the log lines)
And that’s pretty much it! We’re now able to reliably and quickly download data from GH Archive across arbitrary date ranges. In a future post I’ll get this code organized and in a public repo, and show how it can be processed so that DuckDB can query it. Stay tuned!